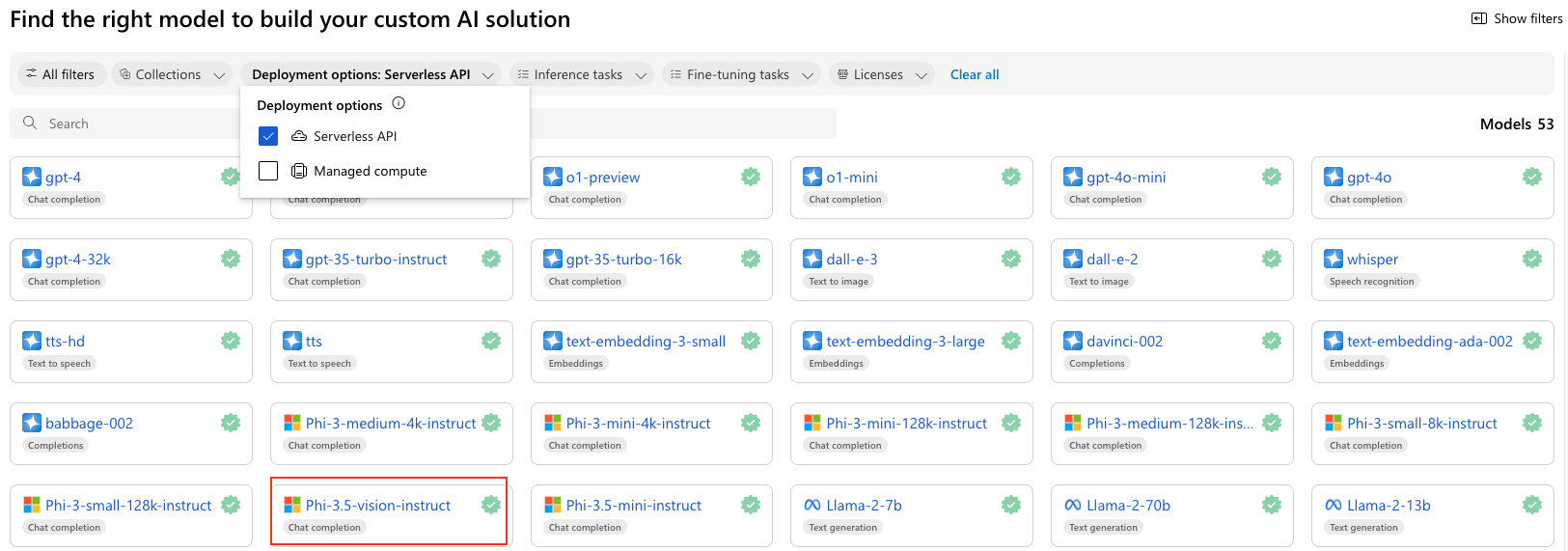
今天我們來用 model catalog 部署多模態的 AI 模型。
我們來部署 Phi-3.5 Vision-Instruct 。這是一款由 Microsoft 開發的多模態 AI 模型,屬於 Phi-3 模型家族。這個模型可以處理文本和圖像的結合輸入,並且它有對於高品質、具推理能力的資料進行了訓練。它具有 128K 的上下文長度,能夠處理單張或多張圖像,並針對這些圖像生成相應的文本描述、回答問題或進行推理。
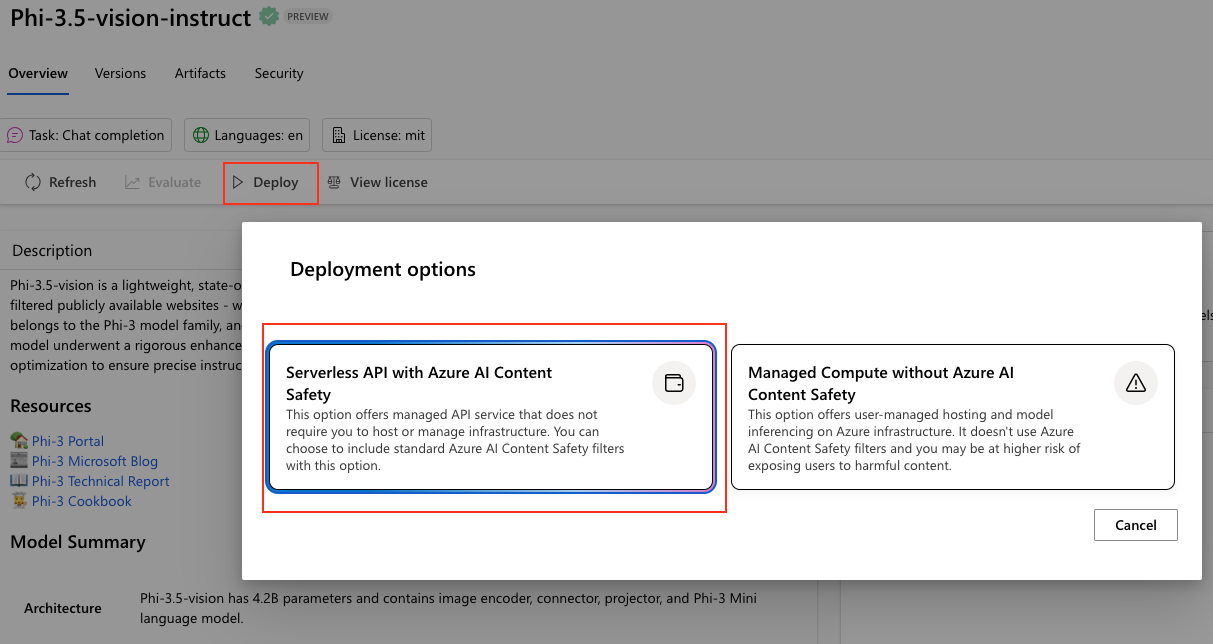
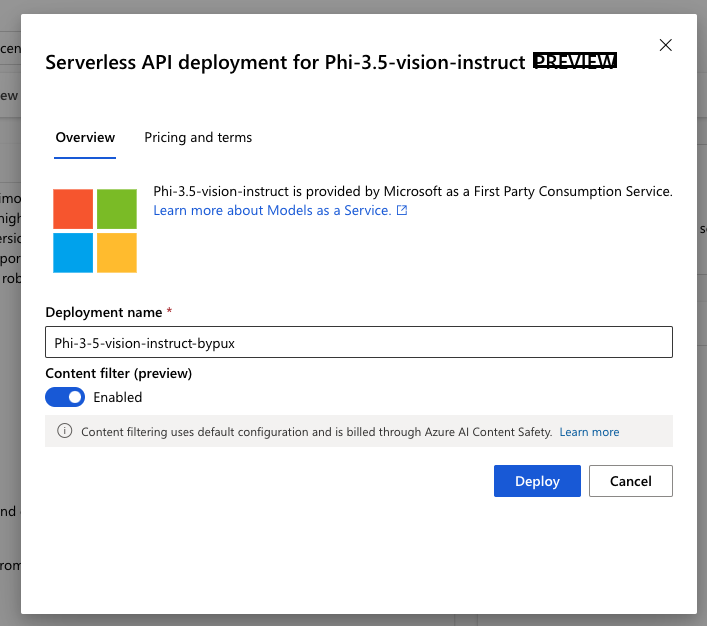
那麼我們現在就來部署起來吧!
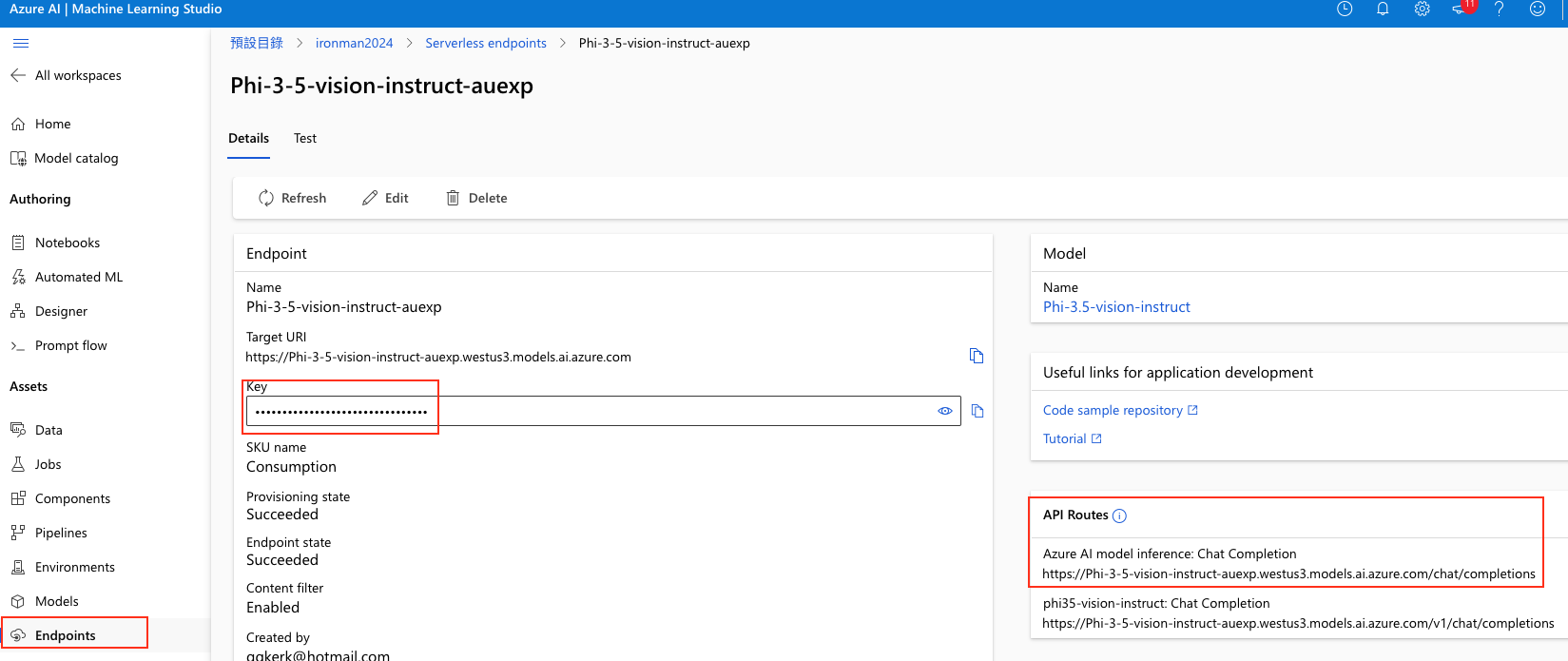
curl -X POST https://Phi-3-5-vision-instruct-auexp.westus3.models.ai.azure.com/chat/completions \
-H "Authorization: Bearer xx" \
-H "Content-Type: application/json" \
-d '{
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://magicpandaengineer.blob.core.windows.net/img/2024ironman/2024ironman-day12-01.png"
}
},
{
"type": "text",
"text": "請用正體中文,描述這張圖片"
}
]
}
]
}'
會得到結果
{
"choices":[
{
"finish_reason":"stop",
"index":0,
"message":{
"content":" 這張圖片是一個中介程式的簡介圖,它標示了如何使用中介程式來設計和開發自己的人工智能(AI)解決方案。圖表裡有許多單元,每個單元都是設計人工智能的不同模型或方法。在圖表中,有一個特定的模型被突出並且被放在其圖類的底部,這是一個名為 'P-1-vision instruct' 的模型,這個模型可能是中介程式的一種特定人工智能解決方案。",
"role":"assistant",
"tool_calls":null
}
}
],
"created":1727279371,
"id":"cmpl-xx",
"model":"phi35-vision-instruct",
"object":"chat.completion",
"usage":{
"completion_tokens":222,
"prompt_tokens":493,
"total_tokens":715
}
}
我們可以看到,它解析出了 P-1-vision instruct,我想只是解析度不夠而已,但是已經很強了,也猜測了這張圖片是什麼?
Phi-3.5 Vision-Instruct 雖然強,但是畢竟是中小型的大語言模型,建議拿來做簡單的辨識就好了。


 iThome鐵人賽
iThome鐵人賽